AI 搜索这周的变化,不只是多了几个引用
本期筛选范围:2026-06-08 至 2026-06-14 发布或收录的内容。
这周看 SEO 和 GEO,我会把几条信息放在一起看。
Semrush 在讲 AI 答案里的 ghost citations,Search Engine Journal 在讲 BrightEdge 的来源角色研究,Google AI Mode 开始把 information agents 推给 Ultra 用户,Semrush 又引用 Cloudflare 的 bot traffic 信号,web.dev 和 Chrome 同时把 agent-friendly 与 WebMCP 安全边界讲得更具体。
单看每条,都是一条新闻。
放在一起看,方向就清楚一点了:AI 搜索不只是回答问题,它正在决定引用谁、点名谁、持续盯什么,以及到了网站以后能不能替用户继续做事。
这对出海团队的影响不是马上重建网站。小吉会更倾向于先做一个判断:GEO 不只是让模型找到网页,而是让模型理解品牌、理解页面、理解下一步动作。
被引用,不等于被记住
Semrush 和 Kevin Indig 这周做了一组研究,分析了 3,981 次域名在 AI 答案里的出现,覆盖 ChatGPT、Google AI Overviews、Gemini 和 Google AI Mode。
里面最值得记住的数据是:约 62% 的 AI 引用没有带来品牌提及。
也就是说,模型可能用了你的页面,但答案正文里没有说出你的品牌。Semrush 把这种情况叫 ghost citations。
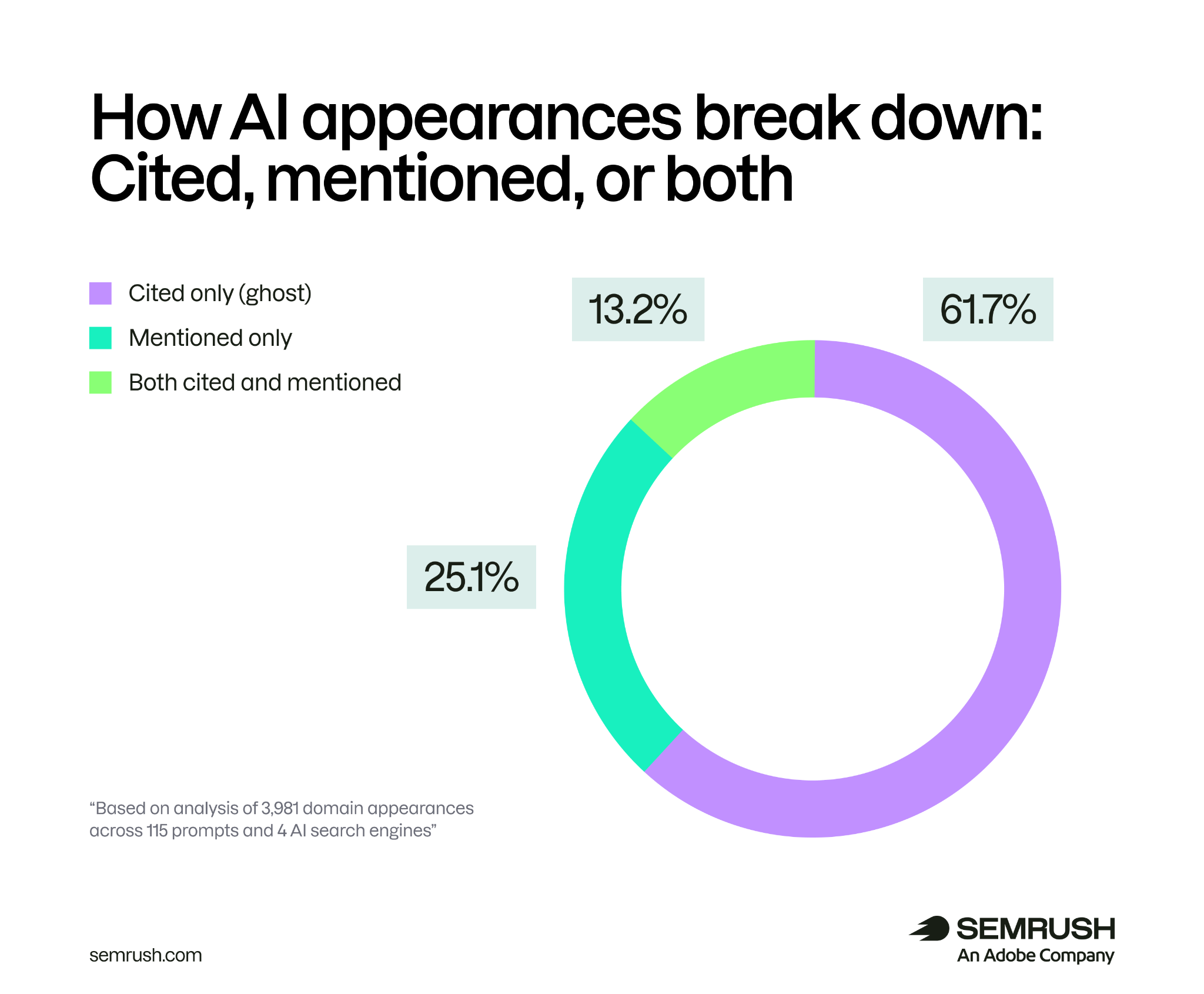
约 62% 的 AI 引用没有同时带来品牌提及——模型用了你的页面,正文里却没有说出你的品牌。
很多团队现在会问:我们的页面有没有被 AI 引用?
这个问题当然重要,但它只问到了一半。如果内容只是脚注,用户未必会记住你。真正进入心智的,往往是答案正文里被说出来的品牌。
这也是为什么强品牌在 AI 搜索里更占便宜。媒体、百科、资料站、评测站,容易变成引用来源。品牌自己如果没有被直接说出来,就会变成模型背后的材料,而不是用户眼前的选项。
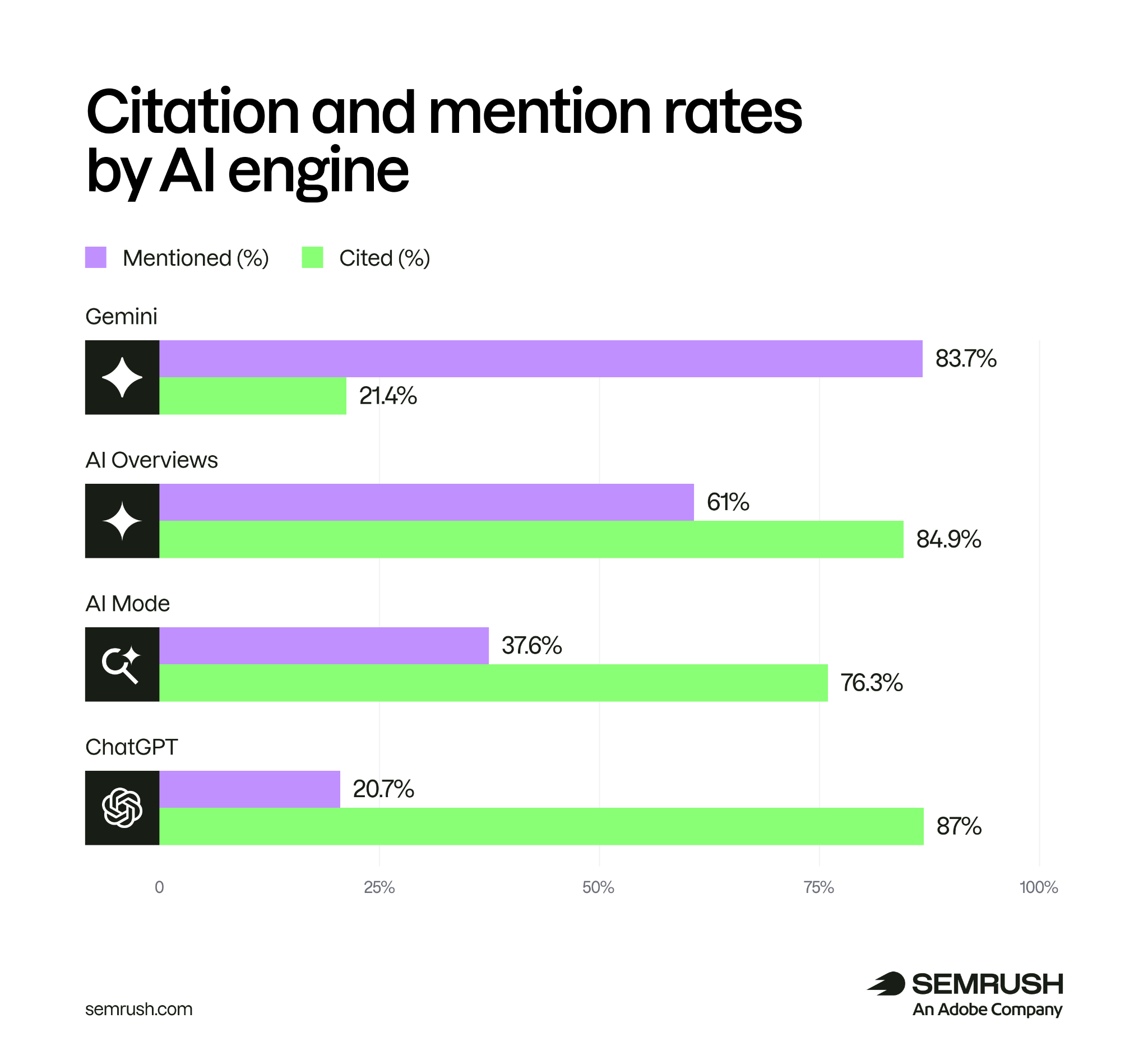
同一个品牌,在 ChatGPT、AI Overviews、Gemini、AI Mode 里被引用和被点名的方式并不一致。
所以 AI 可见度至少要拆开看:
- 页面有没有被引用。
- 品牌有没有被点名。
- 点名时有没有链接。
- 有没有带来 AI 平台推荐流量。
只看 citation,容易产生错觉。你会觉得自己已经被 AI 看见了,但用户可能完全不知道你是谁。
这组研究里还有一个细节很有用:比较型查询更容易带来品牌提及。比如 best X for Y、A vs B、top tools for 这类问题,模型更需要列出具体品牌。
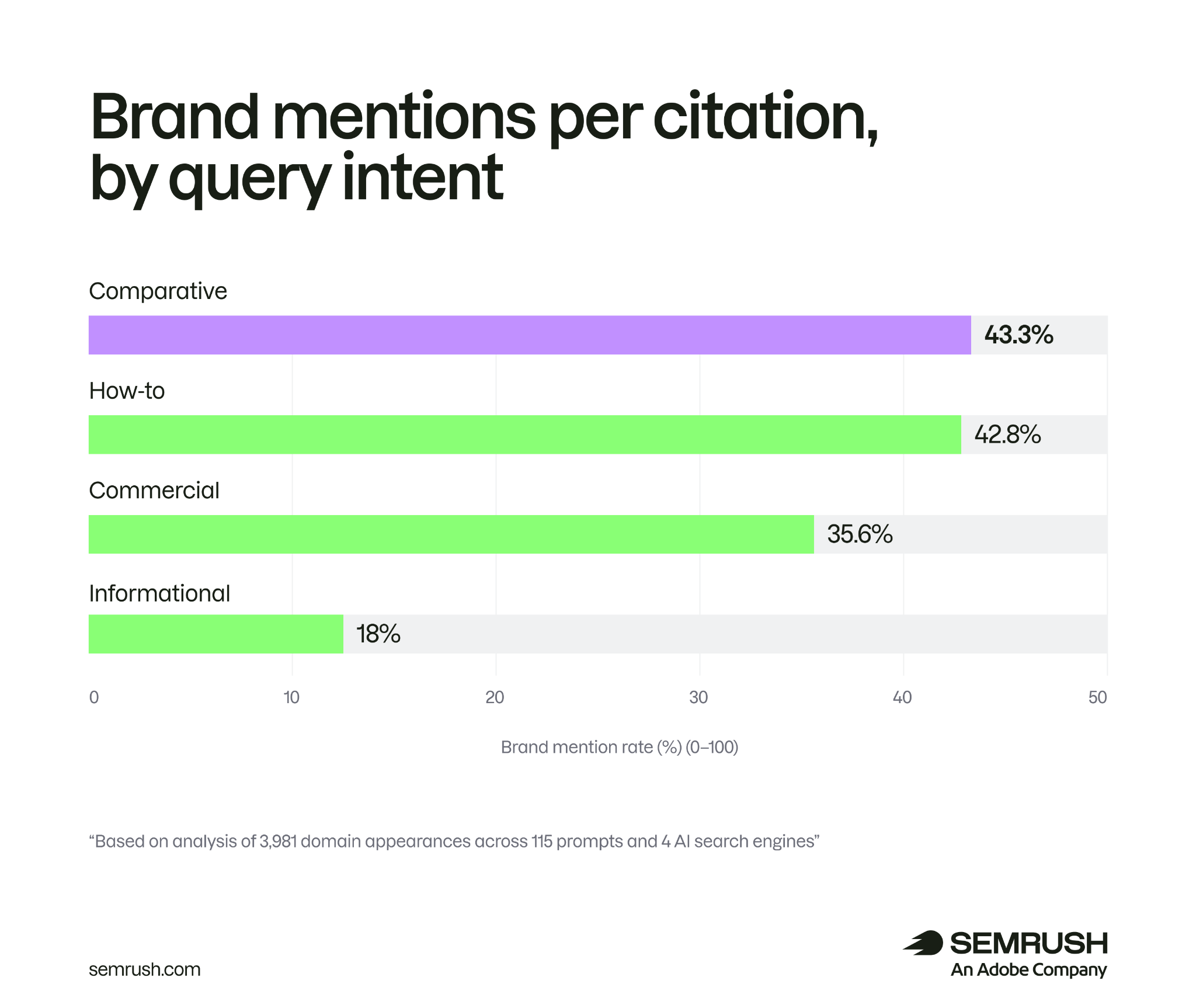
比较型查询(best X for Y、A vs B、top tools for)更容易让模型在正文里点名具体品牌。
这对 SaaS、工具站、出海品牌很实际。
内容不能只停在百科式科普。你要写清楚谁适合你,谁不适合你,你和替代方案差在哪里,你在哪些场景里更好用。
这些内容看起来不像传统 SEO 大词,但更接近 AI 答案里的决策语境。
还有一个容易被忽略的点:国家差异很明显。同一个品牌,在不同市场里的提及率可能差很多。用全球平均值看本地 GEO,判断会变粗。
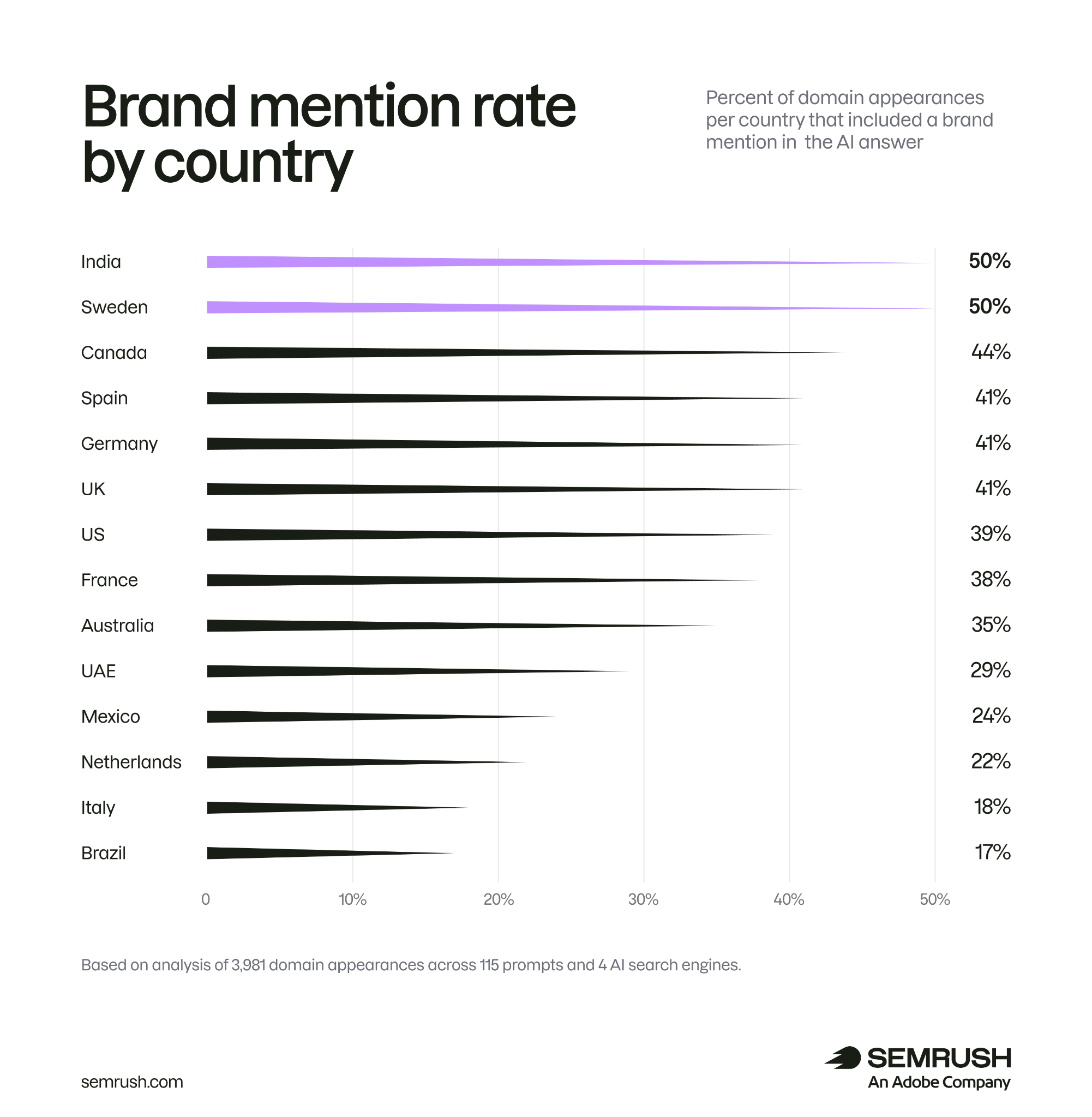
同一个品牌在不同国家市场的提及率差距明显,用全球平均值会把本地问题盖掉。
如果只做一个全球总表,很容易把问题盖掉。更现实的做法,是挑核心市场,分别看 citation、mention 和 linked mention。
同一个来源,在不同答案引擎里角色不一样
Search Engine Journal 解读了 BrightEdge 的一组研究。
我觉得这条信息的重点,不是哪些网站被 AI 引用最多,而是不同答案引擎会给同一种来源分配不同角色。
比如 Reddit。
在 ChatGPT 的引用里,Reddit 更常和 Mayo Clinic、Healthline、Cleveland Clinic、Britannica 这类权威站点一起出现。它像是在补充真实用户经验,也会被放进比较严肃的信息语境里。
但在 Google AI Overviews 里,Reddit 更常和 YouTube、TikTok、Facebook、Instagram 这类平台放在一起,更像社交证明或用户讨论。

同一个 Reddit,在 ChatGPT 里更像权威信息的补充,在 AI Overviews 里更像社交证明——答案引擎给来源分配的角色不一样。
这说明一个很现实的问题:不要把 AI 搜索当成一个统一渠道。
ChatGPT、Google AI Overviews、Google AI Mode、Gemini、Perplexity,对来源的使用方式并不一样。同一个外部平台,在不同系统里可能承担完全不同的功能。
LinkedIn 也类似。B2B、职业、专业服务类问题里,它可能是身份、能力和行业经验的信号。但放到普通消费类问题里,它未必有同样权重。
所以问题不是要不要做 Reddit,也不是要不要做 LinkedIn。
更该问的是:
- 目标用户到底会问哪些问题。
- 这些问题更可能在哪个答案引擎里出现。
- 这个答案引擎更相信哪类来源。
- 我们现在的外部语境,是在帮品牌解释自己,还是只留下了一堆零散提及。
如果你是 B2B SaaS,LinkedIn、行业博客、案例页、评测站、文档站可能要一起看。如果你是消费工具,Reddit、YouTube、评测文章、使用场景页可能更重要。
这里的关键词不是多发渠道,而是来源组合。
AI 搜索不会只看官网。它会看整个网络里别人如何描述你。品牌、社区、评测、教程、对比内容,不只是传播素材,也会变成机器判断你的外部语境。
Google AI Mode 开始把搜索变成后台监控
Google 上周把 AI Mode 的 information agents 推给 Google AI Ultra 订阅用户。
这个功能的变化在于,用户不一定要反复搜索。他们可以让 AI Mode 持续关注某个主题,新信息出现时再收到更新。
Search Engine Journal 引用 Robby Stein 的说法,这些 agents 会在后台持续工作,并给用户发送更新和网页链接。Google 在 I/O 里也提到,这些 agents 会看网页、博客、新闻、社交内容,也会结合实时金融、购物和体育数据。

AI Mode 的 information agents 会在后台持续关注主题,从主动输入 query 转向系统持续监控 topic。
这不是一个小的交互变化。
搜索正在从用户主动输入 query,变成系统持续监控 topic。
以前,内容更新以后,用户再次搜索才有机会看到。现在,某些内容可能会进入后台监控流。尤其是价格变化、产品更新、行业事件、功能发布、风险提醒这类信息。
这对工具类产品、SaaS 和内容站有明显影响。
如果网站只有静态落地页,没有更新日志、版本记录、数据页、价格说明、对比页、研究页,系统就少了一个判断你仍然活跃的事实层。
未来很多问题可能会变成:
- 这个品牌最近有没有发布新功能。
- 这个工具价格有没有变化。
- 这个行业最近有哪些可靠更新。
- 这个产品和替代方案的差异有没有变。
这些问题更适合被持续监控,而不是一次性搜索。
所以我会建议出海团队重新看这些页面:
- Changelog。
- Release Notes。
- Pricing Update。
- Comparison Pages。
- Product Status。
- Security and Compliance Update。
- Research and Benchmark Pages。
这些页面不一定带来很多传统搜索流量,但它们适合被 AI 反复读取。GEO 的一部分工作,会从多写文章,变成维护一层可被机器持续理解的品牌事实。
机器人访问变成主体,旧指标会越来越解释不清
Semrush 上周引用了 Cloudflare CEO Matthew Prince 的说法:bots 已经超过人类流量。
Semrush 文章里提到,Cloudflare Radar 显示 bots 约占网页流量 57%。HUMAN Security 的 2026 State of AI Traffic 报告也显示,2025 年自动化流量增长速度约为人类流量的 8 倍,AI agents 和 agentic browsers 的流量同比增长 7,851%。
Cloudflare Radar 显示 bots 约占网页流量 57%,访问者结构正在从人类转向自动化流量。
这里不要简单理解成爬虫变多了。
更关键的是,网站访问者结构变了。
以前你主要优化用户打开页面后的行为,比如停留时间、跳出率、转化率、点击路径。现在很多访问不会变成传统 session。模型可能只读取页面,代理可能只检查价格,AI 系统可能只抓取一段内容。
这些行为会影响增长,但不一定进入你熟悉的分析面板。
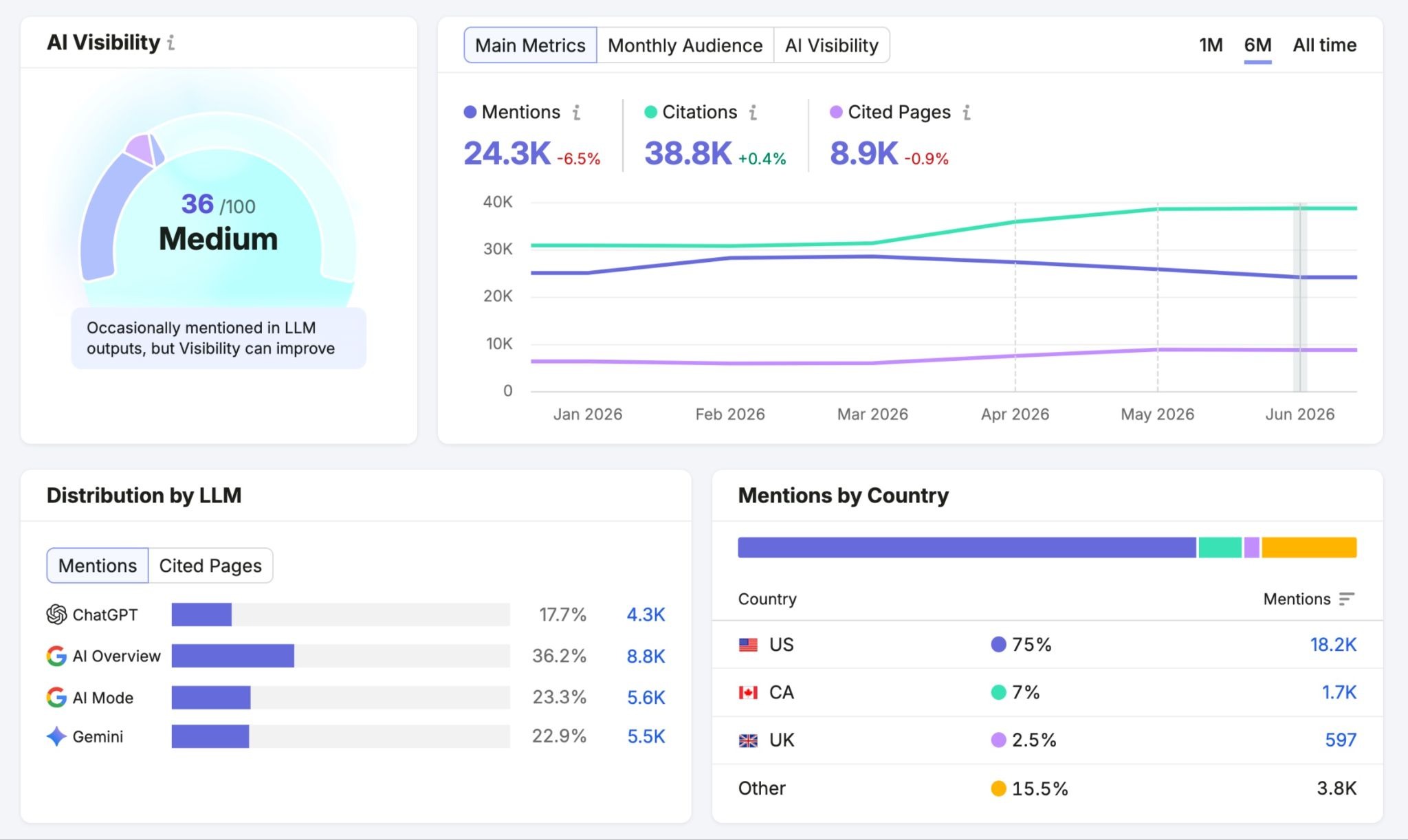
很多 AI 读取行为不会进入传统分析面板,需要专门的 AI 可见度视图来观察。
你可能会觉得 AI 搜索没有带来流量。
但实际情况可能是,页面已经被读取,只是用户没有点击。也可能更麻烦,你本来有机会被读取,但被 robots、WAF、登录墙、JS 渲染、cookie 弹窗挡住了。
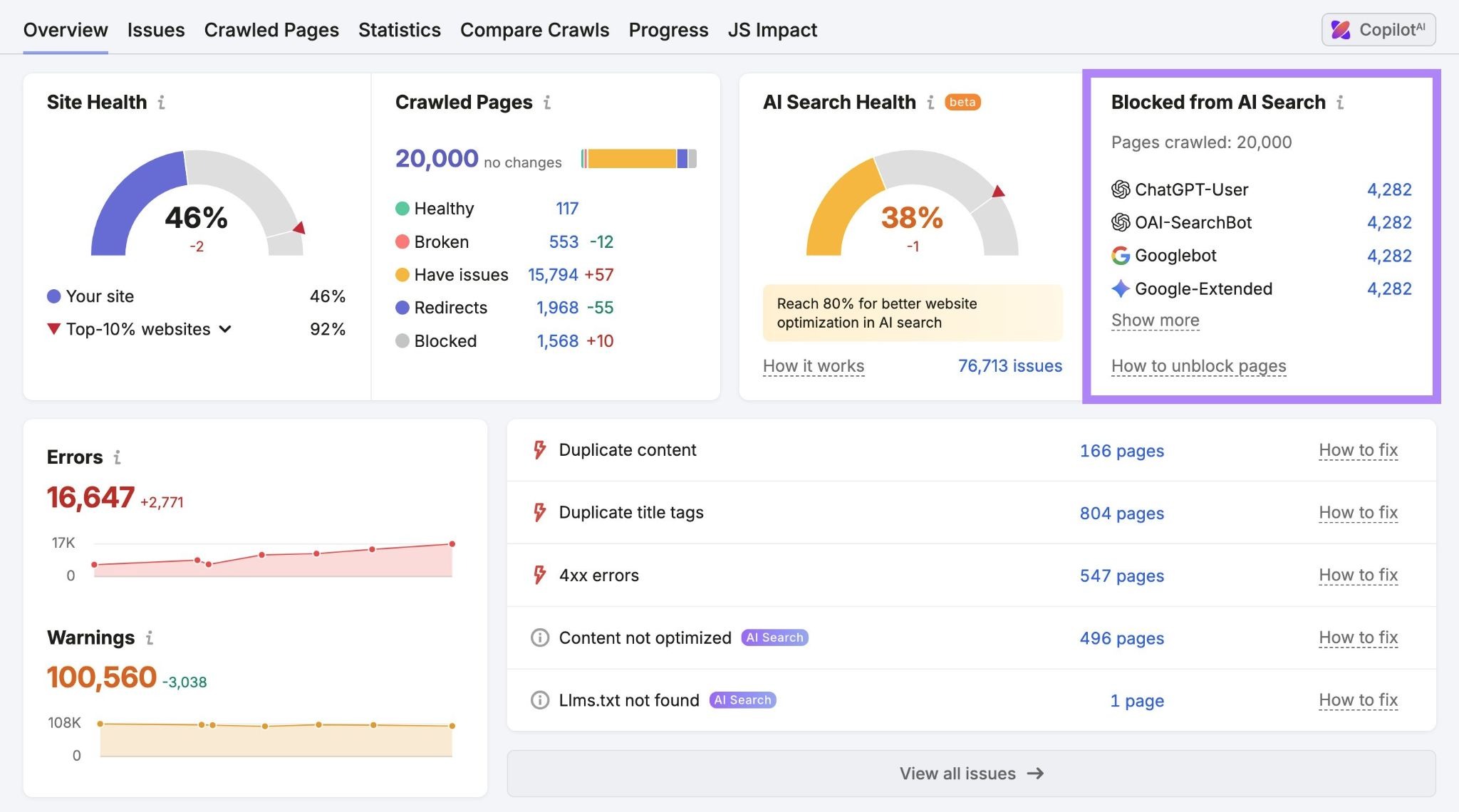
页面可能本来有机会被读取,却被 robots、WAF、登录墙、JS 渲染或 cookie 弹窗挡在门外。
出海团队至少要把三件事单独拿出来看:
- 看 server logs,确认 Googlebot、GPTBot、OAI-SearchBot、PerplexityBot、ClaudeBot、Applebot 这类访问是否被异常阻挡。
- 给核心页面做可抓取检查,尤其是 pricing、comparison、docs、blog、template、tool pages。
- 把 AI 引用、品牌提及、AI referral traffic 单独看,不要全塞回 GSC 和 GA4。
传统 SEO 指标仍然重要。但它们解释不了全部变化。
下一关不是排名,是代理能不能完成动作
Search Engine Journal 这周还有一篇文章,标题很直:AI visibility 以前意味着 citation,2026 年 6 月下旬开始,它会意味着 transaction。
这句话我觉得可以放大看。
Google 在 Android 与 Chrome 里的动作,已经不是只给用户一个答案,而是替用户往前走一步。
Google 的 Android 更新里提到,Gemini Intelligence 会让 Android 更主动。Search I/O 里也讲到 AI agents 会帮助用户订票、预约、规划和处理任务。Search Engine Journal 那篇文章进一步把 Chrome auto-browse 放进同一条线里看:如果代理可以替用户预订、填表、比价、管理订阅,网站不只要能被读,还要能被操作。

AI 可见度的衡量标准正在从 citation 转向 transaction:网站不只要能被读,还要能被代理操作。
这会把很多过去看起来像 UX 细节的问题,变成机器能不能继续执行的问题。
比如:
- 按钮是不是语义化。
- 表单有没有 label。
- 价格是否清楚。
- 套餐是否结构化。
- 弹窗会不会挡住流程。
- 登录墙是否必要。
- 验证码是否让代理直接失败。
- JS 渲染内容是否来得太晚。
这些问题过去也影响用户体验,但现在还会影响代理是否愿意继续执行。
对 SaaS 和工具站,我会先测这些路径:
- 从搜索结果到注册。
- 从 pricing 到选择套餐。
- 从文档到完成任务。
- 从模板页到使用模板。
- 从 comparison 到试用。
- 从博客文章到产品页。
- 从 help center 到解决问题。
不要只问 AI 会不会推荐我们。
还要问 AI 代理推荐之后,能不能顺利完成下一步。这可能会成为新的转化率优化,只是访问者不一定是人。
Agent-ready 的网页,其实先是可访问的网页
Google 的 web.dev 文章 Build agent-friendly websites 讲得很直接:网站现在多了一类新访客,AI agents。
它们可能看截图、读 HTML、解析 accessibility tree,也可能把多种信号放在一起理解页面。

web.dev 把 AI agents 当成网站的一类新访客:它们会看截图、读 HTML、解析 accessibility tree。
Google 给出的建议并不神秘:
- 界面状态要清楚。
- 布局要稳定。
- 不要有幽灵遮罩。
- 使用语义化 HTML。
- 可点击元素要像可点击元素。
- 表单 label 要对应输入框。
- 交互元素不要太小。
听起来像给 agent 做优化,但本质上是重新强调可访问性和语义化。
Search Engine Journal 也把这件事概括成一个判断:Google 的 agent-friendly checklist,其实是 accessibility audit 的另一种说法。
Google 的 agent-friendly checklist,本质上是一份重新表述的 accessibility audit。
这对很多出海团队反而是好消息。
不需要发明一套全新的 AI 网页规范。先把老问题修好:
- 用真实 button,不要所有交互都写成 div。
- 表单字段写清楚 label。
- 重要内容不要只藏在图片里。
- 弹窗不要挡住主流程。
- 页面加载不要导致布局大幅跳动。
- CTA 状态要清楚。
- 价格、功能、限制写成机器能理解的结构。
这些动作不会只服务 AI,也会改善真实用户体验。
我越来越觉得,未来很多 GEO 工作会和前端基础质量、可访问性、信息架构绑在一起。内容团队、SEO、设计、前端不能完全各做各的。
Agent 安全会成为 GEO 的边界问题
这周还有一个容易被忽视的信号:Chrome 针对 WebMCP 发了安全说明。
WebMCP 的方向,是让网站向 AI agents 暴露工具能力。但 Chrome 也提醒了两个风险:malicious manifests 和 contaminated outputs。
简单说,网站暴露给 agent 的工具定义里,可能藏有恶意指令。可信网站返回的工具结果里,也可能因为用户评论、论坛帖、商品评价、第三方内容,混入恶意指令。

Chrome 对 WebMCP 提醒两个风险:malicious manifests 和 contaminated outputs——页面里的文字可能变成 agent 的输入。
这里真正值得注意的是:页面里的文字不再只是内容,它可能变成 agent 的输入。
如果 agent 把所有文本都当作可信指令,就会出问题。
这对 GEO 有一个长期影响。网站不仅要说明我是谁、我提供什么,还要说明哪些内容可信,哪些内容只是用户输入。
特别是有社区、评论、评价、UGC、插件、API、自动化能力的网站,要尽早建立边界。
几个原则可以先记下来:
- 不默认暴露写入能力。
- 涉及支付、删除、发送、发布,都需要用户确认。
- 用户生成内容要标记为不可信内容。
- 工具输出要限制范围。
- 不要让第三方内容直接进入高权限操作链。
- 对 agent 调用做日志和监控。
这不是传统 SEO 话题,但它会变成 AI 搜索时代的基础设施问题。
一旦代理开始代表用户操作网站,可信度就不只是品牌问题,也会变成安全问题。
先别把 GEO 做成新焦虑
这周的主线,我会这样收一下:
SEO 不再只是争网页排名。它开始同时争 AI 系统里的位置、角色和可执行性。
位置,是你有没有被引用。
角色,是你有没有被点名,以及被当成什么来源。
可执行性,是代理能不能在你的网站上完成下一步。
对出海团队来说,现在不需要把每个新词都变成项目。更现实的是先做五件小事:
- 把 AI 可见度拆成 citation、mention、linked mention、referral,不要只看引用。
- 为核心市场建立 20 到 50 个真实问题,每月测试不同 AI 搜索里的品牌出现方式。
- 给前五个业务页面做一次 agent 和 accessibility audit,重点看表单、按钮、弹窗、结构化信息和加载稳定性。
- 增加对比页、场景页、更新日志、价格说明、替代方案页,让模型更容易理解你适合谁。
- 检查重要 AI crawler 是否被阻挡,同时把 UGC、评论、工具输出视为不可信输入。
长期看,GEO 不会取代 SEO。
它更像是在 SEO 之上多了一层机器理解。
谁能把品牌事实、外部语境、页面结构、任务路径一起做好,谁就更容易被 AI 系统记住。也更容易在用户需要答案和下一步动作时,被拿出来。
参考来源
- Semrush:The Ghost Citations Study
- BrightEdge:Same Users, Same Jobs, Different Doors
- Search Engine Journal:Research Suggests AI Engines Assign Ranking Roles To Sources
- Google:A new era for AI Search
- Search Engine Journal:Google Rolls Out AI Mode Information Agents To Ultra Subscribers
- Semrush:Bot traffic now exceeds traffic from human users
- HUMAN Security:The 2026 State of AI Traffic & Cyberthreat Benchmark Report
- Search Engine Journal:AI Visibility Used To Mean Citation. Late June 2026, It Starts To Mean Transaction
- Google:A smarter, more proactive Android with Gemini Intelligence
- web.dev:Build agent-friendly websites
- Search Engine Journal:Google's Agent-Friendly Checklist Is The Accessibility Audit Restated
- Chrome for Developers:Agent security considerations for WebMCP