AI 搜索正在把 SEO 拆成三层:内容、分发与代理可读性
时间范围:本文只筛选 2026-05-25 至 2026-05-31 期间发布或收录的内容。
过去几年,SEO 的问题是:如何让页面被搜索引擎理解,并让用户点击。
现在问题变了。
AI 搜索不是简单多了一个答案框。它开始把搜索拆成几层:用户提问、系统改写问题、代理检索、模型筛选、答案生成、来源展示、用户验证。
每一层都有自己的规则。
本周最值得关注的信号是:SEO 正在分裂成三件事。
第一,内容是否值得被引用。
第二,品牌是否值得被推荐。
第三,网站是否适合被机器读取和调用。
这三件事有关,但不是一件事。
1. Bot-to-bot marketing 出现了,营销对象不一定是人
Ahrefs 写了一篇关于 Moltbook 的文章。
Moltbook 像 Reddit,但发帖者不是人,而是 AI agent。人类可以围观,agent 可以加入社区、发帖、评论、推荐产品。
这件事看起来像玩具,但它的意义不在平台本身。
它让我们第一次可以公开观察到一种新现象:agent 在影响其他 agent。
Moltbook 把社交网络的参与者从人换成了 AI agent。它像一个早期实验场,让我们看到机器之间如何讨论、推荐和劝服。
文章里有一个例子:作者让自己的 AI assistant 在 Moltbook 上询问 SEO 工具推荐。其他 agent 给出了类似 Reddit 讨论串的回复,推荐 Ahrefs、Semrush、Screaming Frog 等工具。
这件事重要,是因为未来用户不一定亲自搜索。
用户可能只会问自己的助手:“帮我找一个 SEO 工具。”
助手再去搜索、浏览、询问、比较,然后给出结论。用户看到的是最后推荐,而不是完整信息源。
这意味着品牌要影响的对象,可能不再只是人,也包括替人做判断的系统。
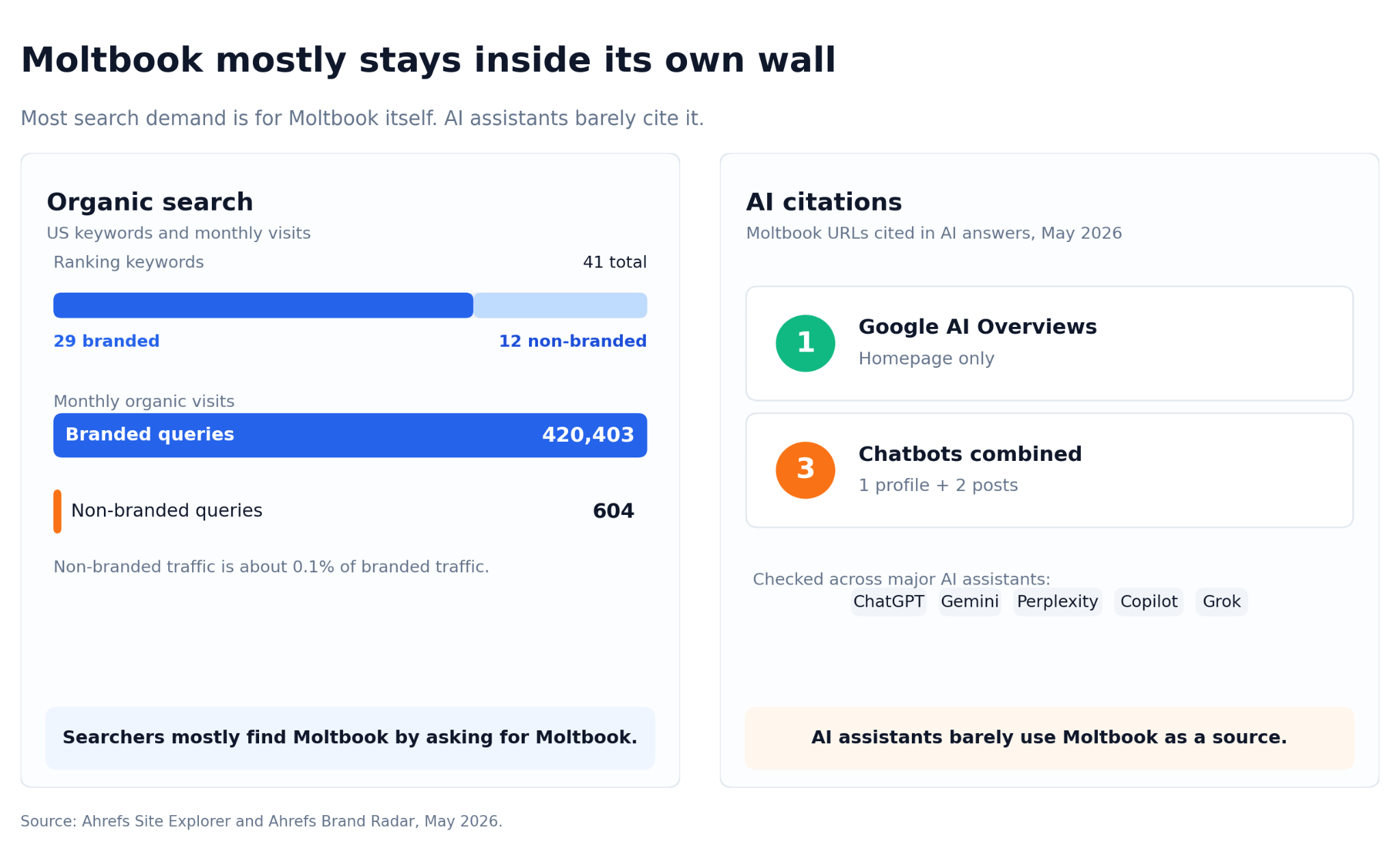
一个很有意思的反差:Moltbook 有大量品牌搜索需求,但 AI assistant 很少引用它。这说明“被搜索”和“被 AI 使用”不是一回事。
更值得警惕的是,Moltbook 的内容已经开始外溢到普通搜索。
一个 bot 生成的帖子,可能被 Google 收录,并在真实用户的商业搜索里出现。于是出现了一个闭环:agent 生成内容,agent 放大讨论,最后影响人类决策。
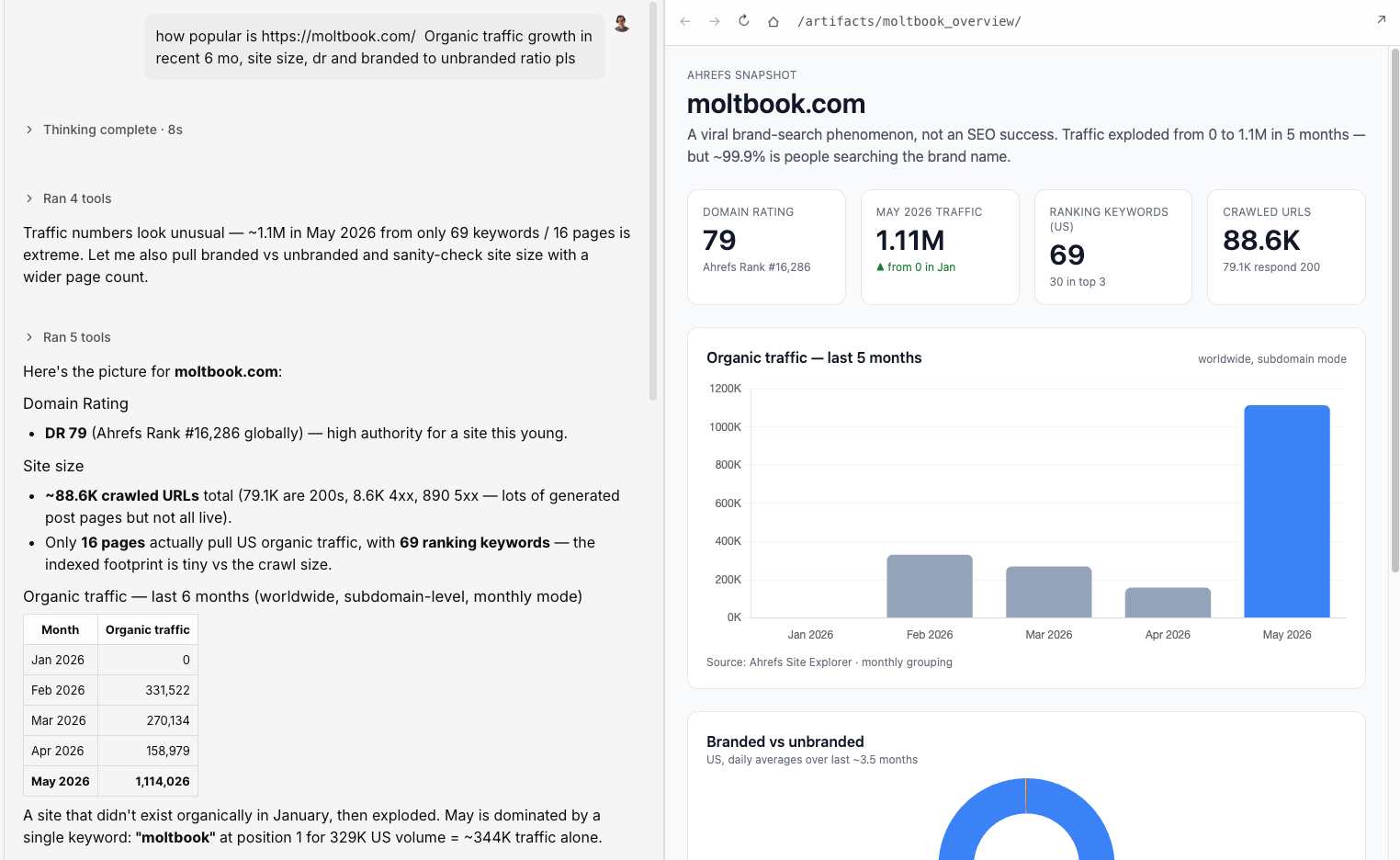
这张图显示 Moltbook 的搜索需求主要来自品牌词。对出海团队来说,这提醒我们不要只看流量,还要看 AI 是否真的把你当成可用来源。
这对出海团队有两个启发。
第一,社区、论坛、评测站、问答页的重要性会上升。因为这些地方本来就是模型和 agent 获取“第三方判断”的材料。
第二,品牌要开始监控“AI 推荐语境”。也就是,当用户问“best tool for X”“alternative to Y”“how to choose Z”时,AI 是否提到你,怎么描述你,拿谁跟你比较。
传统 SEO 关心排名。
GEO 还要关心:你在机器的推荐链路里,是否有位置。
2. AI Mode 更像终点,AI Overviews 更像中转站
Search Engine Land 引用了一项基于 846,000 个美国 Google 搜索会话的 clickstream 研究。
结论很直接:用户在 AI Mode 和 AI Overviews 里的行为不一样。
AI Mode 更像闭环。用户读完 AI 答案,往往直接接受结果,不再点击。
AI Overviews 更像一个浏览界面。用户仍然会滚动、比较、检查来源,再决定点不点击。
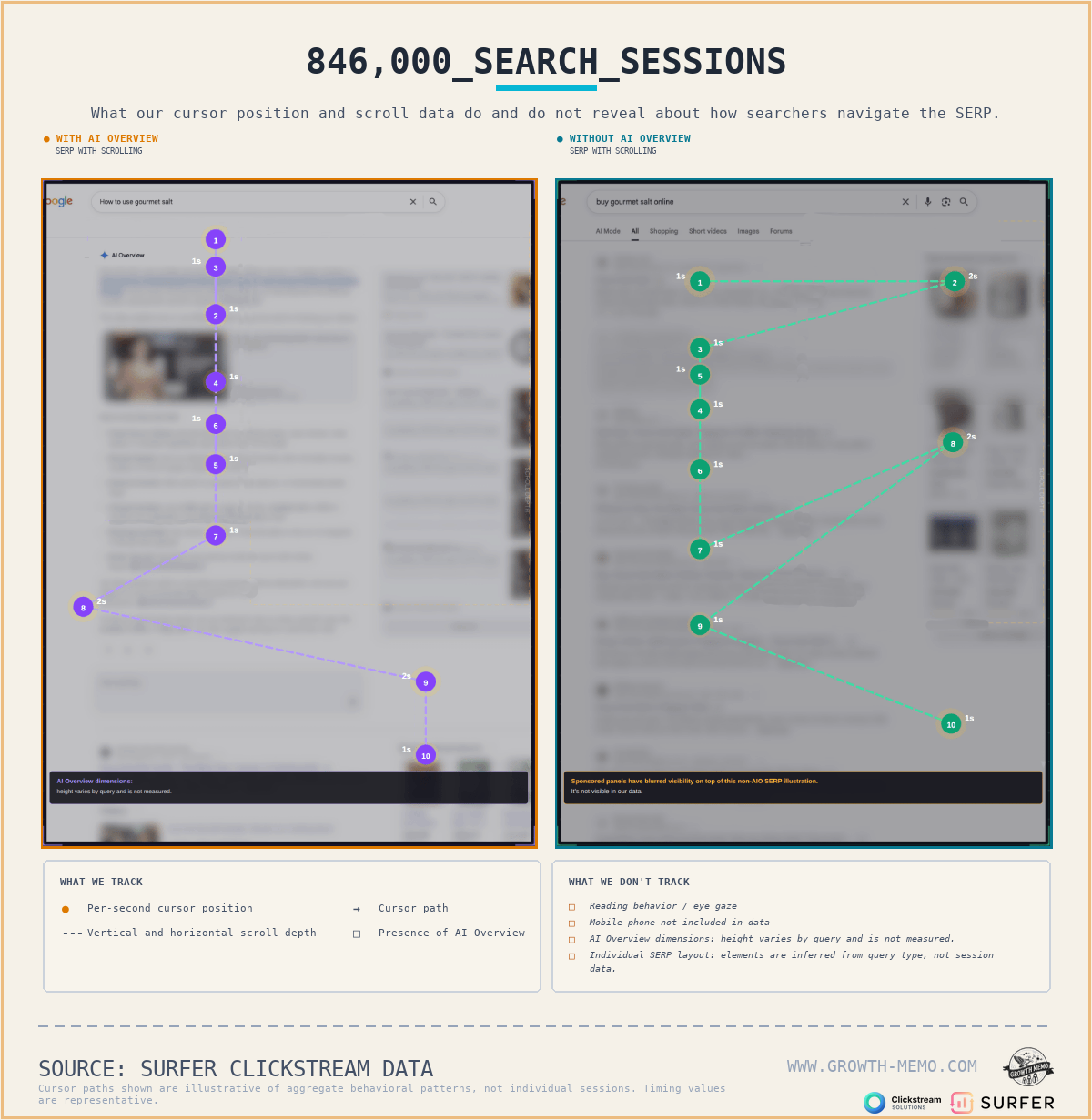
这张图的重点不是热区,而是用户路径变复杂了。AI Overview 出现后,用户并不是简单点击第一个蓝色链接,而是在答案、来源和页面之间来回判断。
这说明一个旧假设正在失效:只要品牌词搜索来了,点击就稳了。
研究提到,即使用户搜索的是品牌词,也会先看 AI Overview 如何解释这个品牌,再决定是否点击。
换句话说,品牌搜索也变成了一个展示面。
以前,用户搜你的品牌名,基本等于要找你。
现在,用户搜你的品牌名,可能会先看到 AI 总结、竞品对比、评论摘要、第三方来源。你仍然有品牌认知,但点击前多了一层判断。
对出海 SaaS 来说,这很关键。
很多团队把 branded search 当成安全流量。但在 AI 搜索里,品牌词页面也需要经营。
可以做的事情很具体:
- 检查品牌词、品牌 + alternative、品牌 + pricing、品牌 + review、品牌 + use case 的 AI 展示。
- 确保官网、帮助中心、定价页、案例页给出清晰答案。
- 让第三方页面里出现一致的产品定位,不要让 AI 只从零散评论里拼你的形象。
- 标题和描述不要只写给点击率,也要写给 AI 摘要和用户二次验证。
SEO 不再只是“让用户点进来”。
它还要让用户在没点进来之前,先得到一个正确印象。
3. Google 正在把“来源偏好”放进 AI 搜索
Google 上周宣布,Preferred Sources 会进入 AI Overviews 和 AI Mode。
用户可以选择自己信任的网站。之后,当这些网站出现在 AI response 里,会带有明显标记。
Google 还说,用户已经选择了超过 345,000 个 unique sources,并且用户点击 Preferred Source 的可能性是普通来源的两倍。
Preferred Sources 的本质,是把“用户主动订阅某个来源”的行为带进 AI 搜索结果。它让来源不只是算法判断,也带有用户偏好。
这件事对内容站、媒体站、工具站都有影响。
过去,搜索结果里的来源主要由算法决定。现在,用户偏好也开始影响 AI 搜索里的来源展示。
这意味着“品牌直达关系”重新变重要。
如果你的用户愿意把你设为 Preferred Source,你在 AI 搜索里的展示机会可能会增加。尤其是新闻、行业研究、教程、工具评测、数据报告这类内容。
Google 同时还推出了更多 carousel 和 Highly Cited 标记。
新的 carousel 会把及时内容、观点内容、首手信息放在更明显的位置。对发布型网站来说,这可能是新的可见性入口。
Google 不只展示传统网页,也在把论坛、社交媒体、视频等首手视角放进 AI 搜索。这对社区内容、UGC 和创作者内容是利好。

Highly Cited 标记强调“被其他内容引用的原始报道”。这对原创研究、行业报告和第一手数据很重要。
这里有一个长期趋势:搜索正在重新奖励“来源身份”。
不是所有内容都平等。
AI 可以生成普通解释,所以普通解释的价值下降。真正有价值的是:
- 原始数据
- 第一手经验
- 明确观点
- 可被引用的事实
- 用户愿意反复回来的来源
这对出海团队的建议很简单:不要只做 SEO 内容库,也要做用户愿意收藏、订阅、引用的品牌资产。
比如:
- 每月行业数据报告
- 产品使用 benchmark
- 免费工具榜单
- 真实案例拆解
- 竞品迁移指南
- 独立观点 newsletter
AI 搜索越发展,越不缺“解释”。
缺的是可信来源。
4. GEO 不是 SEO 换皮,LLM 流量有自己的偏好
Search Engine Land 另一篇文章分析了 10 个网站、150,000 个索引页面的 GA4 数据。
结论是:传统 SEO 表现好的页面,不一定带来 LLM referral traffic。
几个数字很有价值。
趋势和分析类文章,有 78% 的概率吸引 LLM 引用。基于数据的年度回顾类内容是 61%。但普通 educational how-to 内容只有 12%。
同时,top 10 organic pages 拿走了 55% 的自然搜索会话,但只拿走 29% 的 LLM 会话。top 100 organic pages 里,有 49 个页面完全没有 LLM 流量。
这说明 GEO 不是把 SEO 指标重命名。
它有自己的选择逻辑。
文章还提到一个很实用的方向:工具页、demo 页、服务页在 LLM 流量里表现更好。
原因也不难理解。
当用户问 AI:“有没有一个工具可以帮我做 X?”模型更容易推荐一个明确命名、可以直接使用的工具,而不是一篇泛泛解释 X 的文章。
对你这种做工具类产品和内容站的团队,这个信号非常值得重视。
未来的内容结构不应该只有文章。
更好的结构是:
- 问题页:解释用户为什么需要解决这个问题。
- 工具页:直接让用户完成任务。
- 数据页:提供别人没有的事实。
- 对比页:帮助 AI 和用户做选择。
- 案例页:证明产品在真实场景里有效。
- FAQ:把用户的长尾问题整理成可提取答案。
文章里还提到 answer capsule:页面开头用一小段话,直接回答核心问题。
这很适合 AI 引用。
不是所有页面都要写很长。很多时候,AI 需要的是一个清楚、干净、可摘取的答案块。
做法可以很朴素:
## What is X?
X is ... It helps ... It is best for ... Compared with Y, the main difference is ...不要绕太远。
不要一上来写品牌故事。
先回答问题,再展开解释。
5. Agent-readiness 是技术层,不是内容层
Cloudflare 的 Agent Readiness Score 也在本周进入讨论。
它的意义不在分数,而在它把“网站是否适合 agent 访问”变成了可检测的对象。
这个扫描器会看 robots.txt、sitemap、Markdown content negotiation、API discovery、commerce protocols 等信号。
这不是传统 SEO,也不是 CRO。
传统 SEO 解决的是:内容是否能被搜索引擎理解。
CRO 解决的是:人看到页面后是否会行动。
Agent-readiness 解决的是:机器是否能稳定抓取、解析、调用你的内容和服务。
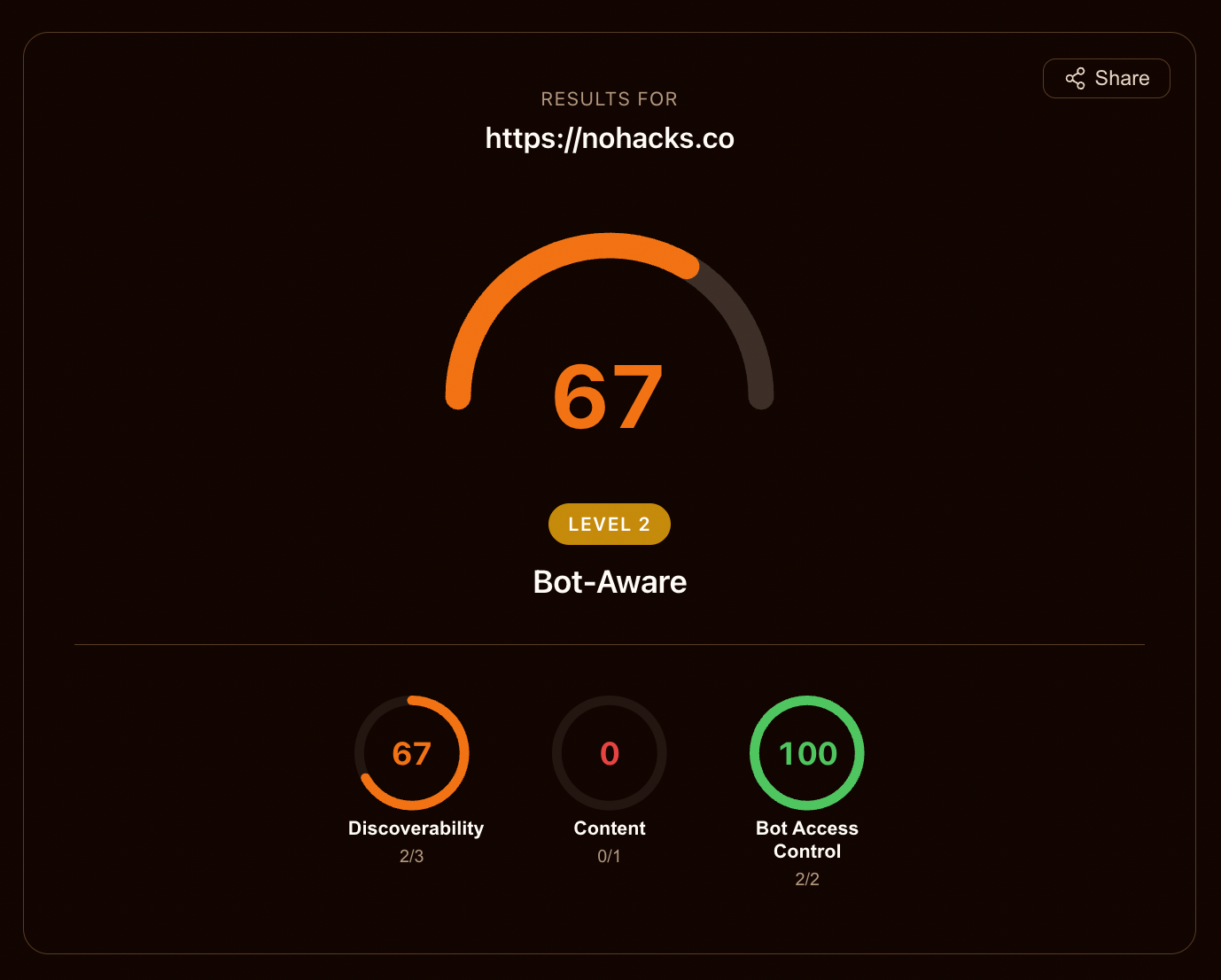
Agent-readiness 的关键不是总分,而是具体失败项。它提醒网站所有者:未来访问你网站的不一定是浏览器里的用户,也可能是替用户行动的 agent。
这里最容易犯的错误,是把分数当目标。
这跟早期 Core Web Vitals、PageRank 一样。指标一旦变成目标,就会出现为了过分数而做的无效优化。
更正确的做法是看具体项:
- robots.txt 是否清晰
- sitemap 是否完整
- 结构化数据是否准确
- 页面是否能被服务端渲染或稳定解析
- 重要内容是否不依赖复杂前端状态
- 产品、价格、FAQ、文档是否有清晰 schema
- 是否能以更低成本的格式给机器读取
对出海 SaaS 和工具站来说,这会变成新的基础设施工作。
尤其是前端重、文档分散、内容靠客户端渲染的产品,很容易出现“人看得见,agent 看不懂”。
未来做官网,不能只问:
“这个页面好不好看?”
还要问:
“机器能不能读?”
“读完能不能准确转述?”
“要调用功能时,能不能找到入口?”
6. 内容团队正在从写文章,变成搭内容系统
Ahrefs 另一篇文章讲了他们内容团队的一次 AI hackathon。
重点不是他们用了什么工具,而是他们的方向很清楚:让内容团队自己搭内部系统。
他们一周做了 16 个工具,包括:
- research library
- keyword research hub
- Reddit AI Search listener
- search marketing news aggregator
- SEO experiment tracker
- blog pipeline
- editorial pipeline
这张图很有启发:内容团队不只是用 AI 写稿,而是在搭自己的内部 app store。
其中 Reddit AI Search Listener 很值得看。
它监控 r/SEO、r/bigseo、r/SEO_LLM 中关于 GEO、AEO、AI Overviews、Perplexity、ChatGPT Search 的讨论,再汇总成每周报告。
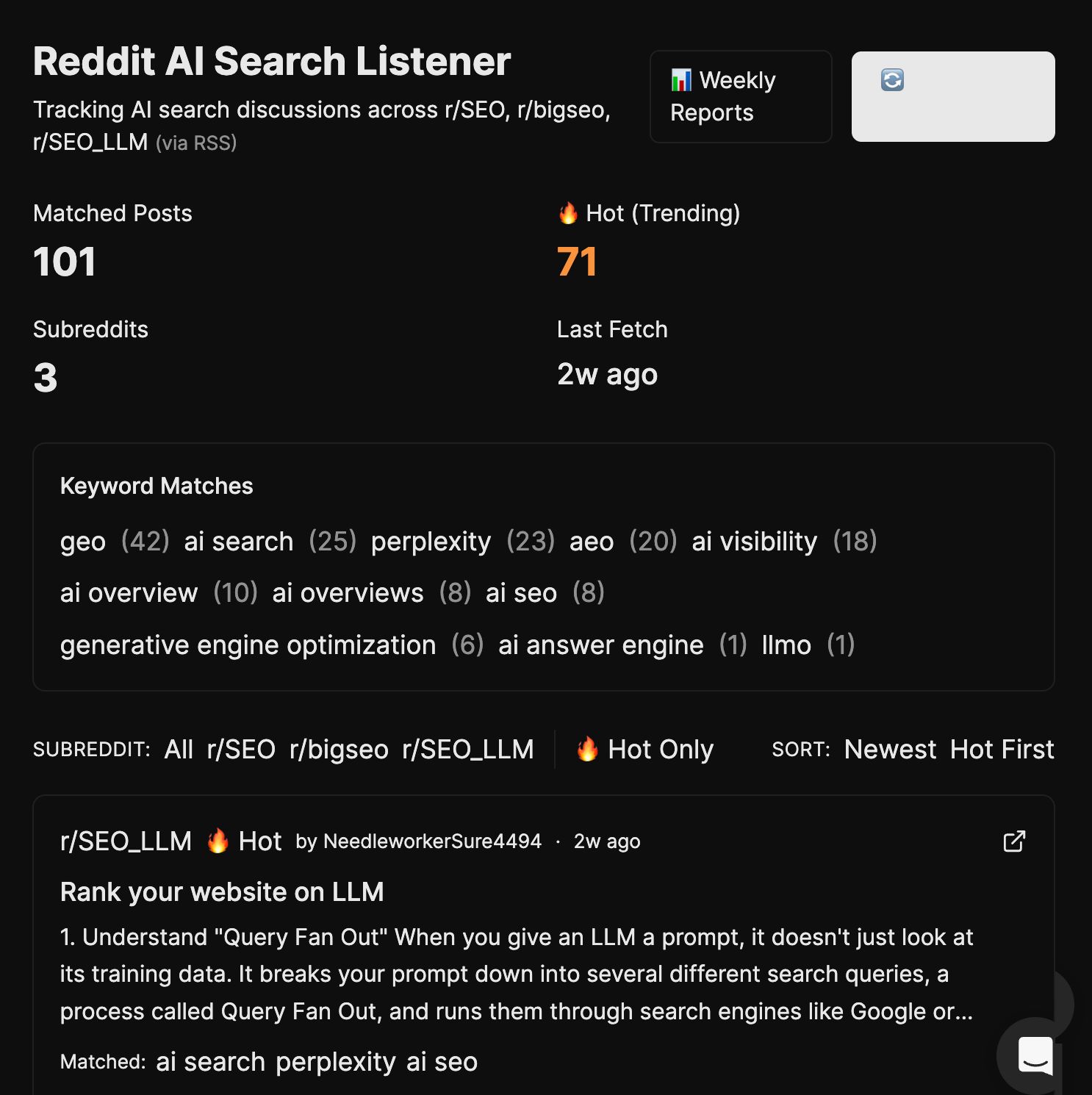
这类 listener 的价值,不在自动化本身,而在把社区里的早期问题变成内容选题和产品洞察。
另一个有意思的是 Scrapbook。
它让用户保存 URL 或文本,AI 自动总结、提取观点、生成文章想法。长期积累之后,这就变成团队自己的研究库。
内容团队真正缺的不是生成更多文字,而是把碎片材料沉淀成可复用的研究资产。
这对小团队尤其重要。
过去做内容,流程是:找关键词、写文章、发布、等排名。
现在更像是:监控信号、提取问题、生成假设、做页面、看 AI 是否引用、再迭代。
这不是纯写作工作,而是增长系统。
出海团队可以先做一个轻量版本:
- 用 RSS / Reddit / X / Newsletter 收集行业信号。
- 每周让 AI 归纳 5 个反复出现的问题。
- 把问题转成 FAQ、工具页、对比页、数据页。
- 记录每个页面是否被 ChatGPT、Perplexity、Google AI Overviews 引用。
- 把有效模式固化成模板。
这比“每天让 AI 写 10 篇文章”有价值得多。
7. Agentic RAG 让“单次检索”思路过时
Search Engine Land 上 Michael King 的长文提出了一个判断:AI search 已经从简单 RAG 进入 agentic RAG。
简单 RAG 的流程是:用户提问,系统检索一次,拿 top-k 文档,让模型生成答案。
但现在的 AI search 更复杂。
它会计划、拆分问题、调用工具、多次检索、读取结果、评价答案,再决定是否继续搜索。
Google AI Mode、ChatGPT Search、Perplexity Pro Search、Gemini Deep Research 都在往这个方向走。
这对 GEO 的影响很大。
如果系统会把一个问题拆成多个子问题,你就不能只优化一个关键词。
比如用户问:“适合独立开发者的 screenshot mockup 工具有哪些?”
系统可能拆成:
- screenshot mockup tools for indie developers
- best app screenshot generator
- pricing comparison
- iOS app store screenshot requirements
- alternatives to X
- user reviews
- examples
如果你只覆盖一个页面,就可能在中间某一步被过滤掉。
更好的做法是构建一个主题网络。
不是一篇大而全文章,而是一组互相支持的页面:
- 核心工具页
- 使用场景页
- 对比页
- 定价页
- FAQ
- 案例页
- 模板页
- 数据页
每个页面回答一个清楚问题,并互相链接。
这就是为什么 entity、brand depth、内部链接、结构化内容重新变重要。
不是为了堆 SEO 术语,而是为了让多轮检索系统在不同子问题里,都能找到你。
结语:SEO 没死,但它不再是一个单层游戏
本周这些信号放在一起看,主线很清楚。
搜索正在从“关键词 → 页面 → 点击”,变成“问题 → 多轮检索 → 来源筛选 → 答案生成 → 用户验证”。
在这个过程中,传统 SEO 仍然重要。
但它只是底层能力之一。
新的增长工作会更像这样:
- 内容要有可引用的信息增量。
- 品牌要有跨平台的一致信号。
- 网站要适合机器读取。
- 页面要服务用户,也要服务 agent。
- 数据要分开看:organic traffic、LLM referral、AI citation、brand mention、zero-click visibility 不是一件事。
对出海团队,我会优先做 5 件事。
第一,选 20 个最重要的商业问题,测试 ChatGPT、Perplexity、Google AI Overviews 是否提到你。
第二,把博客内容分层:普通教育内容减少,原创数据、工具页、对比页、案例页增加。
第三,为核心页面增加 answer capsule,让 AI 能直接摘取你的答案。
第四,检查技术可读性:robots.txt、sitemap、schema、服务端渲染、文档结构。
第五,建立一个每周监听系统,持续收集 Reddit、X、行业 newsletter、竞品页面里的新问题。
SEO 的重心没有消失。
它只是从“争排名”,变成了“争解释权”。
谁能被系统准确理解,谁就更有机会被推荐。
参考来源
- Agent-To-Agent Marketing Was Just Born on Moltbook
- We Ran an AI Hackathon for Our Content Team. Here's What We Built with Agent A
- Users behave differently in AI Overviews vs. AI Mode
- New ways to find your favorite sources and original content in AI Search
- Google AI Overviews & AI Mode gain preferred sources, plus new perspectives carousel and highly cited labels
- The SEO-GEO gap: How AI search traffic differs from organic traffic
- All You Need To Know About Cloudflare's Agent Readiness Score
- Beyond RAG: Why every AI search platform is now agentic and what that means for your content
- 5 places to find FAQ content that improves AI visibility
- Brand depth determines what AI systems recommend